R语言临床预测模型讲义2:R语言在医学统计学中的应用
- 2026-04-20 11:51:36
医学统计学常用方法与R语言实战讲义
一、常用方法总结
summary()table(), describe(), twogrps() | |||
t.test()wilcox.test(), chisq.test() | |||
aov()kruskal.test() | |||
cor.test() | |||
glm()coxph(), lm() | |||
survfit()coxph() |
需要同学们注意的是,本课程为实战课,所以不会和大家讲那些晦涩难懂的统计学具体原理和算法,我们作为医生医学生,其实只需要知道:在什么情况下应该用哪种统计学方法来实现我们的需求?
对于统计学原理,我会给大家总结一些课外链接,等大家有时间可以点进去查看:【人话统计学概念:T检验】 https://www.bilibili.com/video/BV1YcbAznEjr/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957[https://www.bilibili.com/video/BV1YcbAznEjr/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957]【人话统计学概念:ANOVA方差分析】 https://www.bilibili.com/video/BV1aPbAzEEcd/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957[https://www.bilibili.com/video/BV1aPbAzEEcd/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957]【【人话统计学概念】统计学经典两类错误 :第一类错误,第二类错误 不再傻傻分不清楚!核心记忆法~】 https://www.bilibili.com/video/BV1YkbGz5Ewk/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957[https://www.bilibili.com/video/BV1YkbGz5Ewk/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957]【人话统计学概念:置信区间!】 https://www.bilibili.com/video/BV14PtwziE6S/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957[https://www.bilibili.com/video/BV14PtwziE6S/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957]【彻底搞懂P值:P< 0.05到底在告诉我们什么?】 https://www.bilibili.com/video/BV1CJagzwEHJ/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957[https://www.bilibili.com/video/BV1CJagzwEHJ/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957]【【人话统计学概念】一次搞懂卡方检验三大类型:独立性检验、同质性检验、拟合优度检验!】 https://www.bilibili.com/video/BV15tHQzrECH/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957[https://www.bilibili.com/video/BV15tHQzrECH/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957]【logistic回归到底是什么?一个视频讲清楚!小白轻松上手】 https://www.bilibili.com/video/BV1RZ421N74k/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957[https://www.bilibili.com/video/BV1RZ421N74k/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957]【直观理解皮尔逊相关系数(r)和决定系数(r平方)】 https://www.bilibili.com/video/BV1Cx4y1r7v5/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957[https://www.bilibili.com/video/BV1Cx4y1r7v5/?share_source=copy_web&vd_source=676b76a2a1b388f37fdec94c879bb957]
二、描述性统计(Descriptive Statistics)
适用场景
一般是论文的第一和第二个表,用于展示样本特征,如年龄、性别比例、实验指标。
基础R代码示例
1 2 3 4 5 6 7 8 9 10 11
# 示例数据data <- data.frame(age = rnorm(100,60,10),sex = sample(c("Male","Female"),100, replace =TRUE))# 基本描述summary(data$age)table(data$sex)library(tidyverse)data%>% group
结果解读
summary(age)输出均值、中位数、四分位数。table(sex)显示男女比例。
三、两组比较
t 检验/非参数检验与可视化
1、研究场景
我们想比较两组(如男性 vs 女性)在某一连续变量(如年龄)上的差异。在医学研究中,这属于两独立样本均值比较的典型问题。如果是kllip分级这种等级变量,则应该直接使用非参数检验或者卡方检验进行组间差异比较
2、数据准备
1 2 3 4
data <- data.frame(age = rnorm(100,60,10),sex = sample(c("Male","Female"),100, replace =TRUE))
随机生成一个示例数据,复制进去运行就可以啦
3、基本描述性统计
1 2 3 4 5 6 7 8 9
summary(data$age)table(data$sex)library(tidyverse)data1 <- data %>% group_by(sex)%>%summarise(Mean = mean(age),Sd = sd(age),Median = median(age))data1
4、正态性检验(Shapiro–Wilk 检验)
在进行t检验前,需要判断数据是否服从正态分布。原因: t检验的前提是假定总体近似正态分布。若不满足,可改用非参数检验(Mann–Whitney U检验)。
1 2 3 4 5 6 7 8 9 10 11
# 按组进行正态性检验shapiro.test(data$age[data$sex =="Male"])shapiro.test(data$age[data$sex =="Female"])shapiro.test(data$age[data$sex])# 若样本量较大(n>50),可以用QQ图辅助判断ggplot(data, aes(sample = age, color = sex))+stat_qq()+stat_qq_line()+facet_wrap(~sex)+theme_bw(base_size =14)+labs(title ="正态性检验QQ图")
解释:
p > 0.05 → 近似正态分布,可用 t 检验;
p ≤ 0.05 → 拒绝正态假设,应使用 Mann–Whitney U 检验。
5、两组比较(t 检验 / 非参数检验)
1 2 3 4 5 6 7 8 9
data <- as.data.frame(data)data$sex <- as.data.frame(data$sex)data$sex <- as.factor(data$sex)t.test(age ~ sex, data = data)test1 <- t.test(age ~ sex, data = data)test1$p.value# 若不满足正态分布test2 <- wilcox.test(age ~ sex, data = data)
data$sex <- as.factor(data$sex)运行后报错:
1 2 3 4
data$sex <- as.factor(data$sex)错误Jxtfrm.data.frame(:无法 xtfrm 数据帧#需要运行:data <- as.data.frame(data)
6、绘图与结果展示
1. 直接用原始数据画箱线图(推荐)
1 2 3 4 5 6 7 8 9 10 11 12
ggplot(data = data, aes(x = sex, y= age, colour = sex, fill = sex))+geom_boxplot()+labs(x ="Gender",y ="Age",title ="Distribution of Age by Gender")+theme_bw(base_size =14)+annotate(geom ="text", label = paste0("p = ",signif(test1$p.value,3)),x =1.5, y =max(data$age)+5)+annotate(geom ="segment",x =1, xend =2,y =max(data$age)+2, yend =max(data$age)+2,linewidth =0.3)
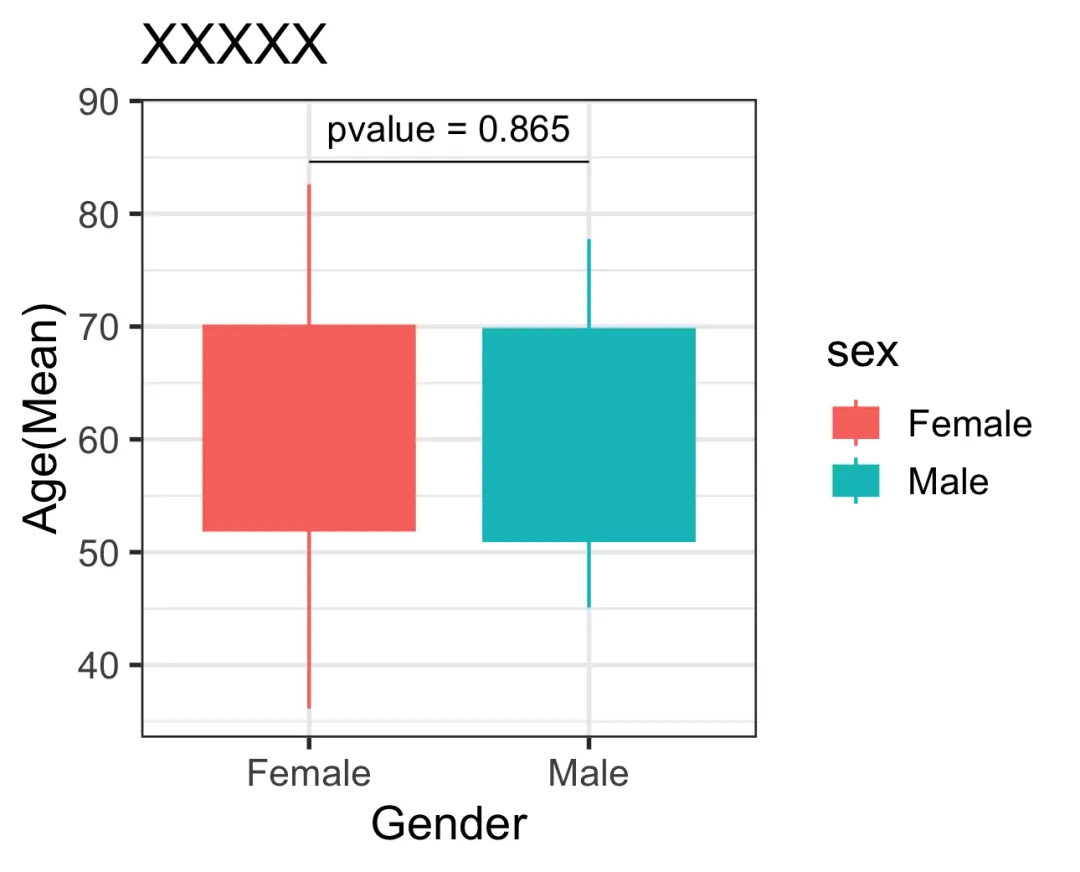
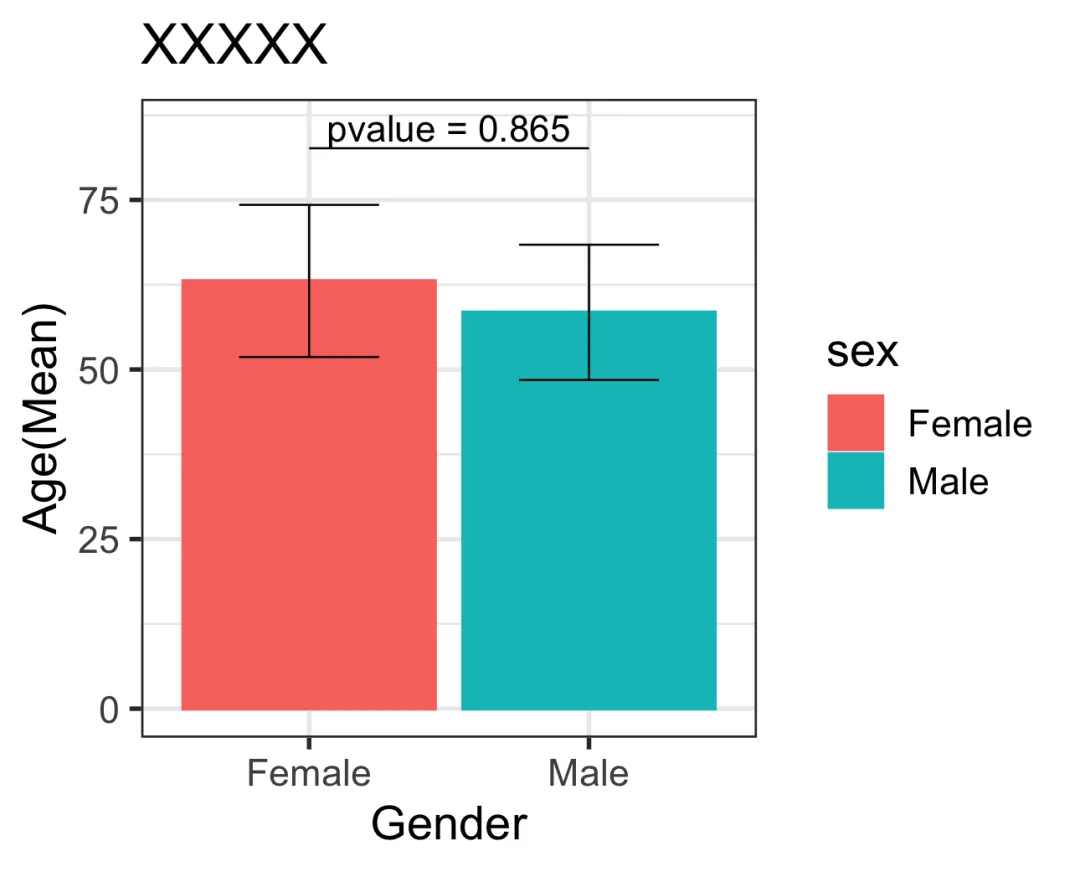
2. 带误差棒的条形图
1 2 3 4 5 6 7 8 9 10 11 12 13 14
ggplot(data = data1, aes(x = sex, y= Mean, colour = sex, fill = sex))+geom_col()+labs(x ="Gender",y ="Age(Mean)",title ="Group Comparison (Mean ± SD)")+theme_bw(base_size =14)+geom_errorbar(aes(ymin = Mean - Sd, ymax = Mean + Sd),width =0.5, color ="black", linewidth =0.3)+annotate(geom ="text", label = paste0("p = ",signif(test1$p.value,3)),x =1.5, y =max(data$age)+3)+annotate(geom ="segment",x =1, xend =2,y =max(data$age), yend =max(data$age),linewidth =0.3)
卡方检验(分类变量)
卡方检验用于分类变量之间的关联分析,常见于以下研究情境:
比较男女在疾病患病率上的差异; 比较不同治疗组在结局上是否有显著不同; 检查某变量是否与结局相关(如吸烟与肺癌)。
示例数据
我们直接用R模拟一个示例数据,表示**性别(Male/Female)与是否患病(Yes/No)**的关系。
1 2 3 4 5 6 7
### 构造示例数据 ####set.seed(123)data <- data.frame(sex = sample(c("Male","Female"),200, replace =TRUE),disease = sample(c("Yes","No"),200, replace =TRUE, prob =c(0.4,0.6)))table(data$sex, data$disease)
这里的
prob = c(0.4, 0.6)是用于设置疾病在两组中的比例,也是随机创建数据的参数,不需要管他,你也可以改成prob = c(0.3, 0.7)等任何比例
理论简介
卡方检验(Chi-square test)比较的是实际观测频数与理论期望频数的差异。
原假设(H₀):两变量独立无关。 备择假设(H₁):两变量存在关联。 适用条件: 分类变量; 理论频数 ≥5 的格子应占比 ≥80%。 若频数太小可用 Fisher精确检验( fisher.test())。
卡方检验与Fisher检验
1 2 3 4 5 6 7 8
### 卡方检验 ####tbl <- table(data$sex, data$disease)chisq.test(tbl)chisq.test(tbl, correct =F)chisq.test(data$sex,data$disease)### Fisher精确检验(当样本量较小或期望频数<5) ####fisher.test(tbl)
correct = F表示不加校正**,即直接使用标准的 Pearson 卡方检验,SPSS 的 “Pearson 卡方检验” 默认 不加连续性校正, 但会在输出表格里单独列出一行 “Continuity Correction (Yates)”,因此,你在 SPSS 里看到的 Pearson χ² 值,对应的是chisq.test(tbl, correct = FALSE)的结果。
提取 p 值:
1 2
test1 <- chisq.test(tbl)test1$p.value
可视化:堆叠百分比条形图
用于说明分类比例结构差异。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
library(tidyverse)data1 <- data %>%group_by(sex, disease)%>%summarise(n = n())ggplot(data1, aes(x = sex, y = n, fill = disease))+geom_bar(stat ="identity", position ="fill", color ="black")+scale_fill_brewer(palette ="Set2")+labs(x ="Gender",y ="Ratio",title ="Disease Distribution by Gender")+theme_bw(base_size =14)+annotate("text", x =1.5, y =1.05,label = paste0("p = ",signif(test1$p.value,3)))
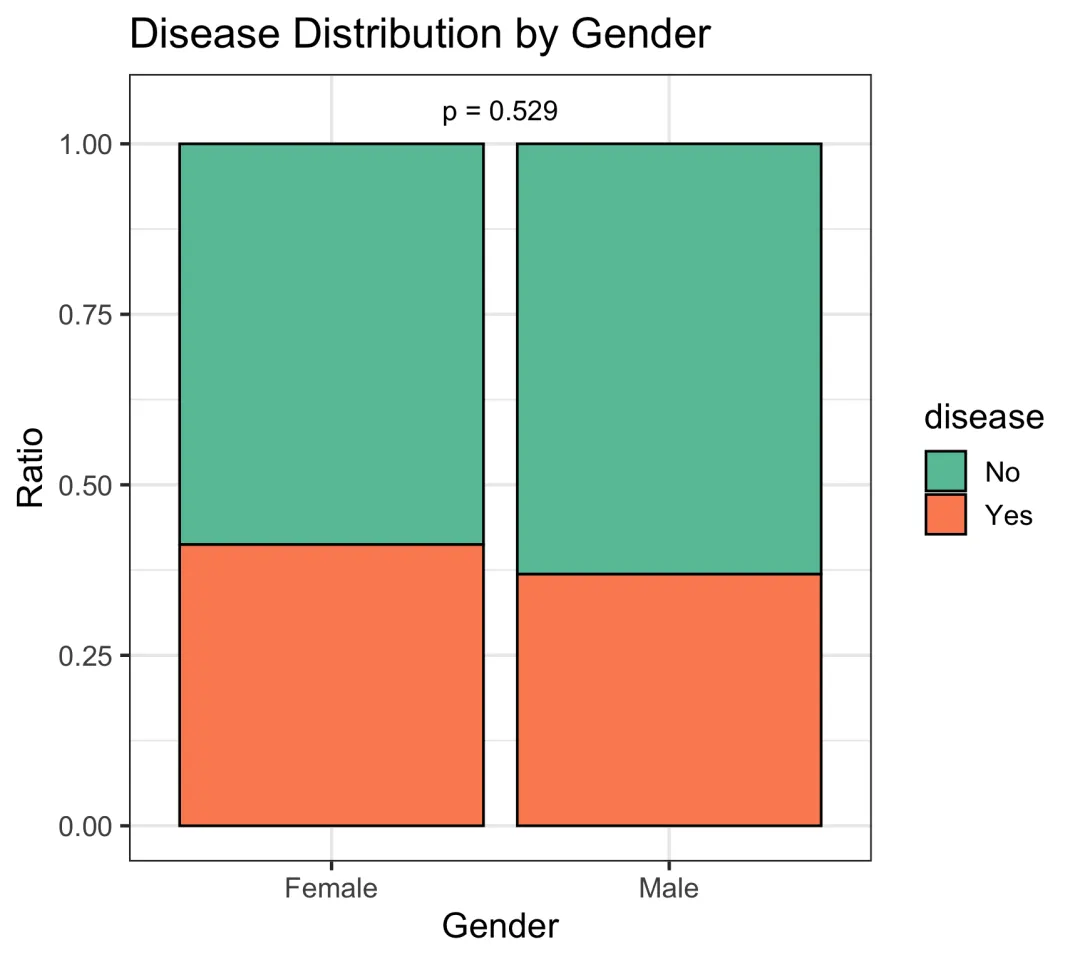
四、多组比较
1. 单因素方差分析(One-way ANOVA)
一、研究场景
在医学研究中,若我们要比较三个或以上独立组在一个连续变量上的均值差异,就需要使用 单因素方差分析(One-way ANOVA)。
常见应用场景:
比较三种治疗方案的疗效(连续结局)是否不同; 比较不同年龄组的血压均值; 比较不同BMI分组的骨密度水平。 ⚠️ t检验只能比较两组均值,而 ANOVA 可以同时比较多组差异。
二、理论简介
原假设(H₀): 各组总体均值相等。备择假设(H₁): 至少有一组均值不同。但 ANOVA 不能告诉你“哪两组不同”,此时需进一步进行 多重比较(post-hoc test)。
三、示例数据
1 2 3 4 5 6 7 8 9
set.seed(123)data <- data.frame(group =rep(c("Control","Treatment_A","Treatment_B"), each =40),value =c(rnorm(40,60,8),rnorm(40,65,8),rnorm(40,70,8)))head(data)
四、正态性与方差齐性检验
单因素方差分析要求:
各组数据近似正态分布; 各组方差相等(齐性假设)。
1 2 3 4 5 6
# 正态性(Shapiro–Wilk)by(data$value, data$group, shapiro.test)# 方差齐性检验(Levene检验)library(car)leveneTest(value ~ group, data = data)
若p > 0.05,认为数据满足假设,可进行ANOVA。若p ≤ 0.05,可考虑使用非参数检验(如Kruskal–Wallis)
五、单因素方差分析(ANOVA)
1 2
fit <- aov(value ~ group, data = data)summary(fit)
输出中:
F value:统计量 Pr(>F):p值 若 p < 0.05,说明至少一组均值显著不同。
1 2
pval <- summary(fit)[[1]]$`Pr(>F)`[1]pval
六、事后多重比较(Post-hoc Test)
1
TukeyHSD(fit)可得出各组之间的成对比较结果(含置信区间与p值)。
七、可视化结果(均值±SD 条形图)
与前面章节保持一致的绘图风格
theme_bw(base_size = 14)+annotatep值标注
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
library(tidyverse)data1 <- data %>%group_by(group)%>%summarise(Mean = mean(value),Sd = sd(value))ggplot(data1, aes(x = group, y = Mean, fill = group))+geom_col(width =0.6, color ="black")+geom_errorbar(aes(ymin = Mean - Sd, ymax = Mean + Sd),width =0.3, linewidth =0.3)+labs(x =NULL,y ="Value (Mean ± SD)",title ="Group Comparison by One-way ANOVA")+theme_bw(base_size =14)+scale_fill_brewer(palette ="Set2")+annotate("text", x =2, y =max(data1$Mean + data1$Sd)+2,label = paste0("p = ",signif(pval,3)))
八、可视化结果(箱线图展示)
1 2 3 4 5 6 7 8 9
ggplot(data, aes(x = group, y = value, fill = group))+geom_boxplot(alpha =0.8)+labs(x =NULL,y ="Value",title ="Distribution of Values across Groups")+theme_bw(base_size =14)+scale_fill_brewer(palette ="Set2")+annotate("text", x =2, y =max(data$value)+2,label = paste0("p = ",signif(pval,3)))
九、结果解释
若 p < 0.05:说明至少有一组均值不同; 再结合 TukeyHSD()判断哪两组差异显著;若方差不齐或不满足正态性,可改用下面的Kruskal–Wallis 检验
2. Kruskal–Wallis 检验(非正态)
一、研究场景
当多组连续数据不满足正态分布或方差齐性假设时, 不能使用传统的 ANOVA。 此时应采用 Kruskal–Wallis 检验(又称秩和检验), 它是 ANOVA 的非参数替代方法。常见场景: 样本量较小; 数据偏态分布(如住院天数、费用、评分等); 各组方差明显不齐; 数据为等级资料(ordinal data)。
二、理论简介(了解即可)
Kruskal–Wallis 检验基于**秩次(rank)**而非原始数值。其原理是:将所有样本合并排序后,比较各组秩和的差异。
原假设(H₀): 各组总体分布相同(中位数相等)。备择假设(H₁): 至少有一组的分布不同。具体公式不展示了,大家有兴趣可以了解,但这个不重要。
三、示例数据
1 2 3 4 5 6 7
set.seed(123)data <- data.frame(group =rep(c("Control","Treatment_A","Treatment_B"), each =40),value =c(rlnorm(40,4,0.4),# 对数正态分布rlnorm(40,4.2,0.4),rlnorm(40,4.4,0.4)))
四、Kruskal–Wallis 检验
1
kruskal.test(value ~ group, data = data)输出结果包括:
Kruskal–Wallis chi-squared(检验统计量) df(自由度) p-value(显著性)
1 2
test_kw <- kruskal.test(value ~ group, data = data)test_kw$p.value
五、事后成对比较
Kruskal–Wallis 检验若显著(p < 0.05),同样需要进一步进行成对比较(pairwise comparison):
1 2
pairwise.wilcox.test(data$value, data$group,p.adjust.method ="BH")# Benjamini–Hochberg校正
⚠️ 注意:
多重比较时必须使用 p 值校正(Bonferroni、BH等)。 输出表格展示各组两两比较的显著性差异。
六、可视化展示(共用 ANOVA 绘图)
Kruskal–Wallis 检验基于秩次,但仍可使用 ANOVA 相同的图形展示:
均值±SD条形图(组间差异可视化) 箱线图(展示中位数与分布形态)
📘 直接复用前文绘图代码,仅替换 p 值来源:
1 2 3 4 5 6 7 8 9 10 11
pval_kw <- test_kw$p.valueggplot(data, aes(x = group, y = value, fill = group))+geom_boxplot(alpha =0.8)+labs(x =NULL,y ="Value",title ="Group Comparison (Kruskal–Wallis Test)")+theme_bw(base_size =14)+scale_fill_brewer(palette ="Set2")+annotate("text", x =2, y =max(data$value)*1.05,label = paste0("p = ",signif(pval_kw,3)))
五、基线表R包CBCgrps包推荐
1
library(CBCgrps)下面给出 CBCgrps 在“二分类分组”的核心用法,尽量精简、即插即用。
1) 快速上手
1 2 3 4
library(CBCgrps)data(df)# 内置示例,mort=alive/dead(二分类)tab <- twogrps(df, gvar ="mort")print(tab,quote=TRUE)# 带引号便于粘贴到 Word 后“文字转表格”
twogrps():二组基线表主函数;自动识别变量类型与分布: 分类→卡方/精确;正态数值→均值±SD + t 检验;非正态→中位数[IQR] + Wilcoxon。(mirrors.sjtug.sjtu.edu.cn[https://mirrors.sjtug.sjtu.edu.cn/cran/web/packages/CBCgrps/CBCgrps.pdf])
2) 你的数据(指定变量、保留NA、显示统计量、提取显著变量)
1 2 3 4 5 6 7 8 9 10 11 12
res <- twogrps(df = df,gvar ="mort",p.rd =3,# p值保留3位小数(小于阈值显示 <0.001)norm.rd =2,# 正态变量保留位数sk.rd =2,# 偏态变量保留位数cat.rd =2,# 分类变量比例小数位ShowStatistic =TRUE,# 显示统计量(t/χ²等))print(res,quote=TRUE)library(openxlsx)write.xlsx(res$Table,"tab1.xlsx",rowNames=F,colNames=F)
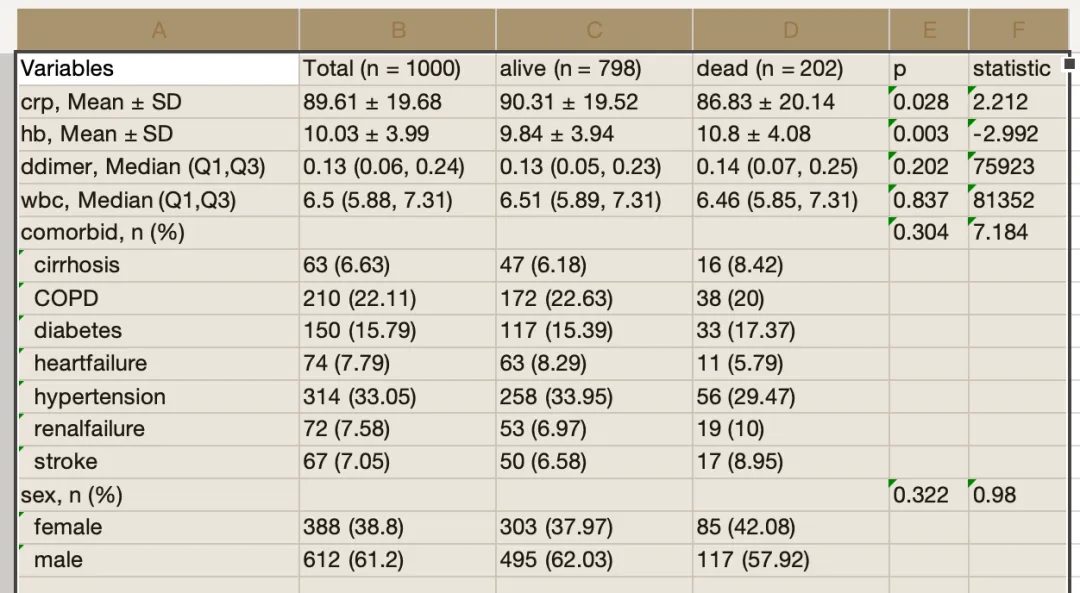
4) 其他常用选项
maxfactorlevels/minfactorlevels:避免把日期/少取值数值错误地当作因子或反之。sim/workspace:当列联表较大时,为 Fisher 精确检验启用蒙特卡洛与更大工作空间。
多组分组请用
multigrps()(用法与参数体系相同)。(mirrors.sjtug.sjtu.edu.cn[https://mirrors.sjtug.sjtu.edu.cn/cran/web/packages/CBCgrps/CBCgrps.pdf])
六、相关分析
相关分析用于判断两个连续变量之间是否存在统计学相关关系。相关关系可分为正相关、负相关和无线性关系常见方法包括 Pearson 相关(正态)和 Spearman 相关(非正态或等级)。
一、示例数据
我们用之前散点图的示例数据来展示分析的过程。
1 2 3 4 5 6 7
library(tidyverse)# 含 ggplot2library(palmerpenguins)# penguins 数据library(ggthemes)# 主题与配色df <- penguins |>select(flipper_length_mm, body_mass_g, species)|>drop_na()# 去除缺失值
二、散点图直观观察
1 2 3 4 5 6 7 8 9 10 11
library(ggplot2)ggplot(df, aes(x = flipper_length_mm, y = body_mass_g))+geom_point(aes(color = species, shape = species), alpha =0.8)+geom_smooth(method ="lm", se =FALSE)+labs(title ="Body mass and flipper length",subtitle ="Adelie, Chinstrap, Gentoo (Palmer Archipelago)",x ="Flipper length (mm)", y ="Body mass (g)",color ="Species", shape ="Species")+theme_bw(base_size =14)
散点图初步显示正相关趋势
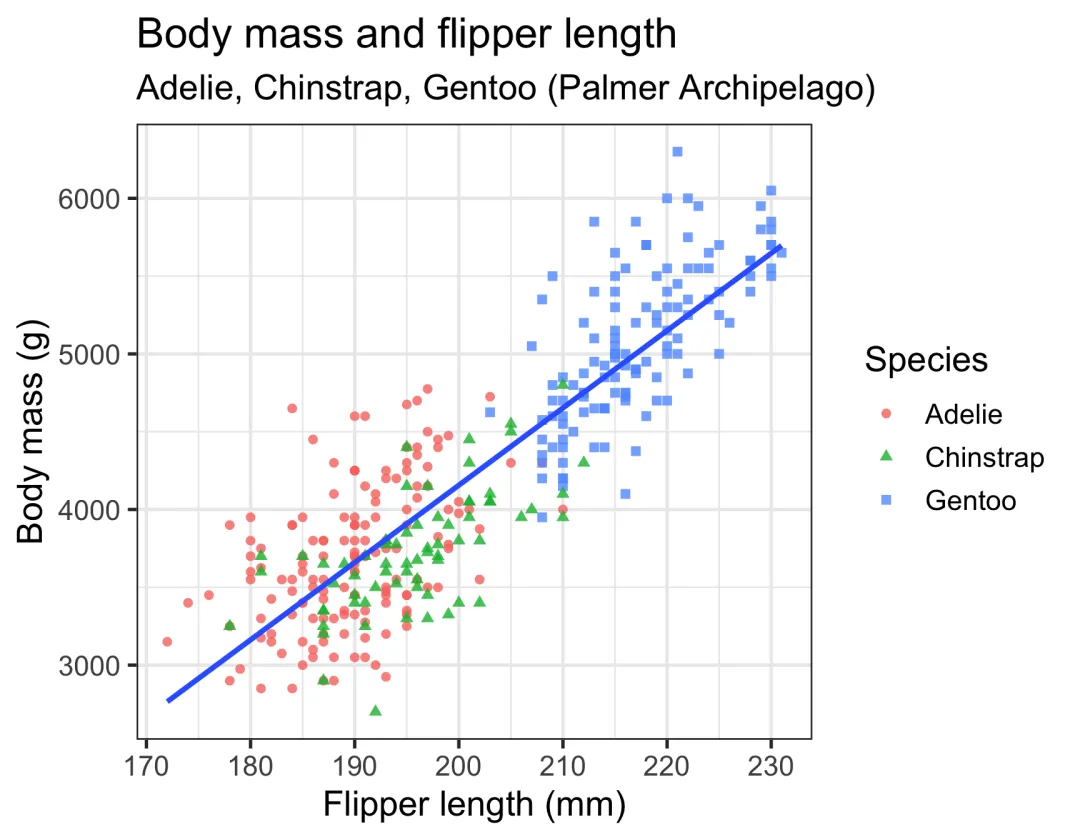
三、正态性检验
1 2
shapiro.test(df$flipper_length_mm)shapiro.test(df$body_mass_g)
若两变量均 p > 0.05 → 近似正态分布,可用 Pearson; 若任一变量 p ≤ 0.05 → 使用 Spearman。
四、Pearson 相关(正态)
当两变量近似正态分布时使用:
1 2
pear <- cor.test(df$flipper_length_mm, df$body_mass_g, method ="pearson")pear
输出内容:
cor:相关系数 r(方向与强度)p-value:显著性水平conf.int:置信区间
五、Spearman 相关(非正态或等级)
若数据不服从正态或为等级资料(如评分、分级):
1 2
spear <- cor.test(data$age, data$bmi, method ="spearman")spear
1 2 3
Warning message:In cor.test.default(...) :Cannot computeexact p-value with ties
原因
Spearman 秩相关系数是基于**秩次(rank)计算的。当变量中存在重复值(ties)时,R 无法计算“精确 p 值”(exact p-value),于是改用近似 p 值(asymptotic p-value)。在企鹅数据集中,flipper_length_mm 或 body_mass_g 有重复测量,因此会触发该提示。
六、可视化与显著性标注
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
library(ggplot2)ggplot(df, aes(x = flipper_length_mm, y = body_mass_g))+geom_point(aes(color = species, shape = species), alpha =0.8)+geom_smooth(method ="lm", se =FALSE)+labs(title ="Body mass and flipper length",subtitle ="Adelie, Chinstrap, Gentoo (Palmer Archipelago)",x ="Flipper length (mm)", y ="Body mass (g)",color ="Species", shape ="Species")+theme_bw(base_size =14)+scale_color_colorblind()+annotate("text",x =min(df$flipper_length_mm)+2,y =max(df$body_mass_g),hjust =0,label = paste0("Pearson r = ",round(pear$estimate,2),", p = ",signif(pear$p.value,3)))
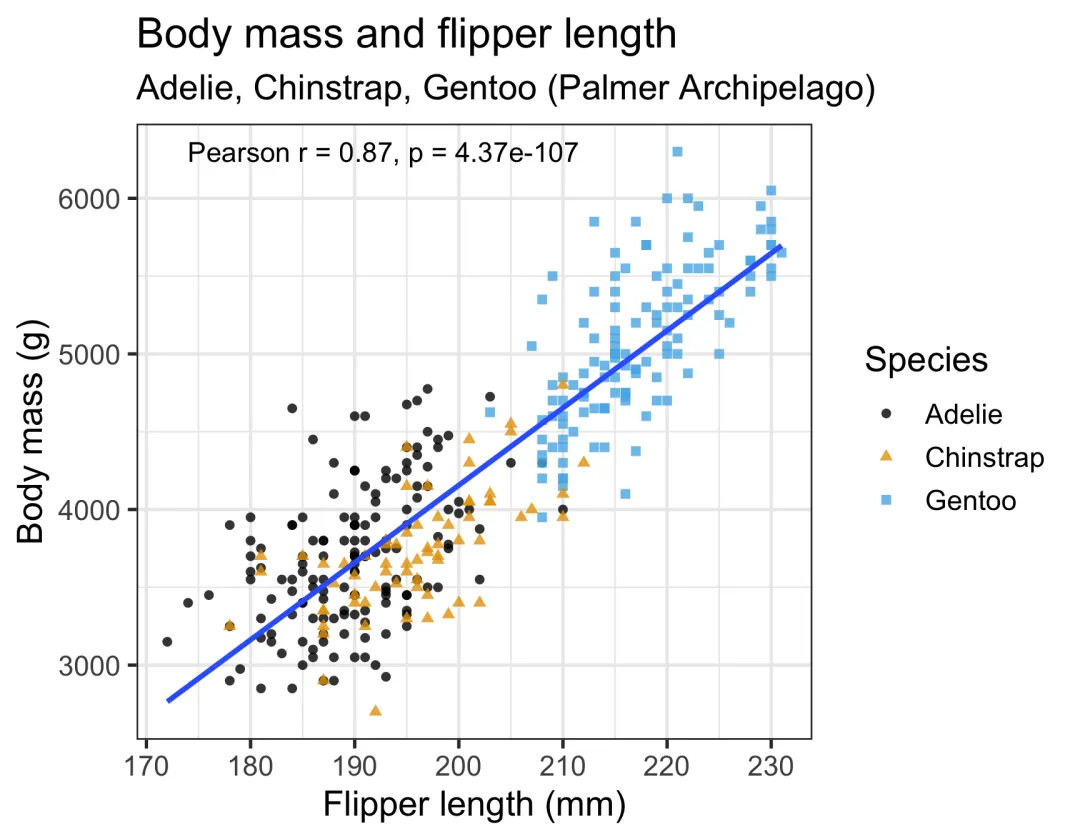
七、结果解释
八、小结
| Pearson | cor.test(x, y, method="pearson") | ||
| Spearman | cor.test(x, y, method="spearman") |
总结:先判断正态性 → 决定 Pearson 或 Spearman;相关显著(p<0.05)则表示两变量随同变化趋势显著。
回归分析的核心目的
| 基本定义 | |
| 核心目标 | |
| 通俗理解 | |
| 常见用途 | |
| 实质 | |
| 常见误区 |
回归分析的本质是:在控制混杂的前提下,用数学模型定量描述自变量与结局变量之间的关系,从而实现解释与预测。
📊 各类回归模型对比总结表
| 线性回归(Linear Regression) | ||||||
| Logistic回归(Logistic Regression) | ||||||
| Cox比例风险回归(Cox Regression) |
简要提示:
若因变量是连续型 → 用 线性回归 若因变量是二分类 → 用 Logistic回归 若研究的是事件发生时间 → 用 Cox回归
讲一下R语言图片导出比例设置的问题
导出图片在正式做课题的时候还是推荐使用 ggsave()或者pdf()/png()函数进行导出临时导出图片可以用Rstudio里面的导出设置——需要提前把图片拉到合适的比例或者在导出页面设置好导出比例; 不推荐导出 tiff格式图片,文件体积大但清晰度也没好太多;最终用于文章的拼图图片格式推荐准备多个格式,优先 pdf、png、jpg,pdf是矢量图,后两种是位图(矢量图位图的小知识[https://blog.csdn.net/xpj8888/article/details/82712238]),如果导出位图,期刊要求的dpi一般不低于300,我们一般导出dpi为600的图片;拼图的教程点进去[https://www.bilibili.com/video/BV1WxYceDEsC/?spm_id_from=333.1387.upload.video_card.click&vd_source=265a67059f8104931870be807f794a7f]看我哔站之前发过的,推荐使用Adobe illustrator这个软件。
随机文章
-
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
- 湖南湘科版1-6年级上下册《心理健康》教案+课件
- 讲义:炎德英才大联考湖南省师大附中2026届高三月考试卷(五)应用文和读后续写
- 2025年九上数学沪科版:期末复习讲义综合检测专项训练知识清单19份含答案解析 | 完整word版文档可下载打印
- 2025年八下物理北师大版:同步讲义与单元测试卷共26份含答案解析 | 完整word版文档可下载打印
- 国考面试内部教案免费领,还送5年国面3年模拟核心资料
- 【北师大7-9年级下册寒假讲义+教师版+学生版】
- 望岳雅集公益诗词学校初级班简明讲义第四讲
- 《有机化学基础》精品讲义/导学案
- 教学能力大赛冲金奖!国赛一等奖教案直接抄
- 大字版《首楞严经讲义》
